
ISMS-P 심사를 앞둔 담당자에게 최근 가장 낯선 질문은 이겁니다 — "직원들이 외부 생성형 AI에 회사 데이터를 넣는 것을 어떻게 통제하고, 그걸 어떻게 증명합니까?" 몇 년 전만 해도 없던 질문이지만, 지금은 정보보호·개인정보 관리체계 점검에서 점점 자주 등장합니다.
문제는 이겁니다. 통제 사실을 증명하려고 "직원이 AI에 뭘 넣었는지"를 원문째 저장하면, 증적을 만들려다 개인정보·기밀을 오히려 대량으로 수집·보관하는 자기모순에 빠집니다. 이 글은 그 함정을 피하면서 심사에 통하는 증적을 준비하는 방법을 다룹니다.
심사는 "직원이 무엇을 입력했는가(원문)"를 요구하지 않는다. 요구하는 건 "통제 정책이 있고, 실제로 작동했고, 위반 시 조치했다"는 검증 가능한 흔적이다. 그 흔적은 원문이 아니라 메타데이터 + 해시로 충분히, 그리고 더 안전하게 성립한다.
왜 지금 생성형 AI 통제가 심사에 들어오나
배경은 규제 흐름의 이동입니다. 생성형 AI가 업무에 빠르게 들어오면서, 개인정보·기밀이 외부 AI 서비스로 흘러가는 경로가 새로운 위험 표면이 됐습니다. 규제·심사 프레임은 이 현실을 따라오는 중입니다.
- 개인정보보호법 생성형 AI 안내서(2025-08) — 개인정보보호위원회가 생성형 AI 활용 시 개인정보 처리 원칙과 안전조치 방향을 정리했습니다. 사내 정책·통제 설계의 참조 기준이 됩니다.
- 관리체계 점검의 확장 — 정보보호·개인정보 관리체계 점검에서 "외부 서비스로의 데이터 이전·유출 통제"를 보는 관점이 강화되며, 외부 생성형 AI 이용이 자연스럽게 그 범위로 들어옵니다.
- 실무 질의의 변화 — 심사 현장에서 "AI 사용 정책이 있는가", "실제로 차단·마스킹이 작동하는가", "위반 시 무엇을 했는가"를 묻는 사례가 늘고 있습니다.
심사는 최신 규제 조문을 그대로 읽지 않는다. "위험이 있는데 통제하고 있는가, 그리고 그것을 증명할 수 있는가"를 묻는다. 생성형 AI는 이제 그 위험 목록에 올라 있다.
심사가 실제로 요구하는 증적 4종
추상적인 "통제한다"가 아니라, 심사 자리에 실제로 올릴 수 있는 네 가지 산출물로 정리하면 준비가 명확해집니다.
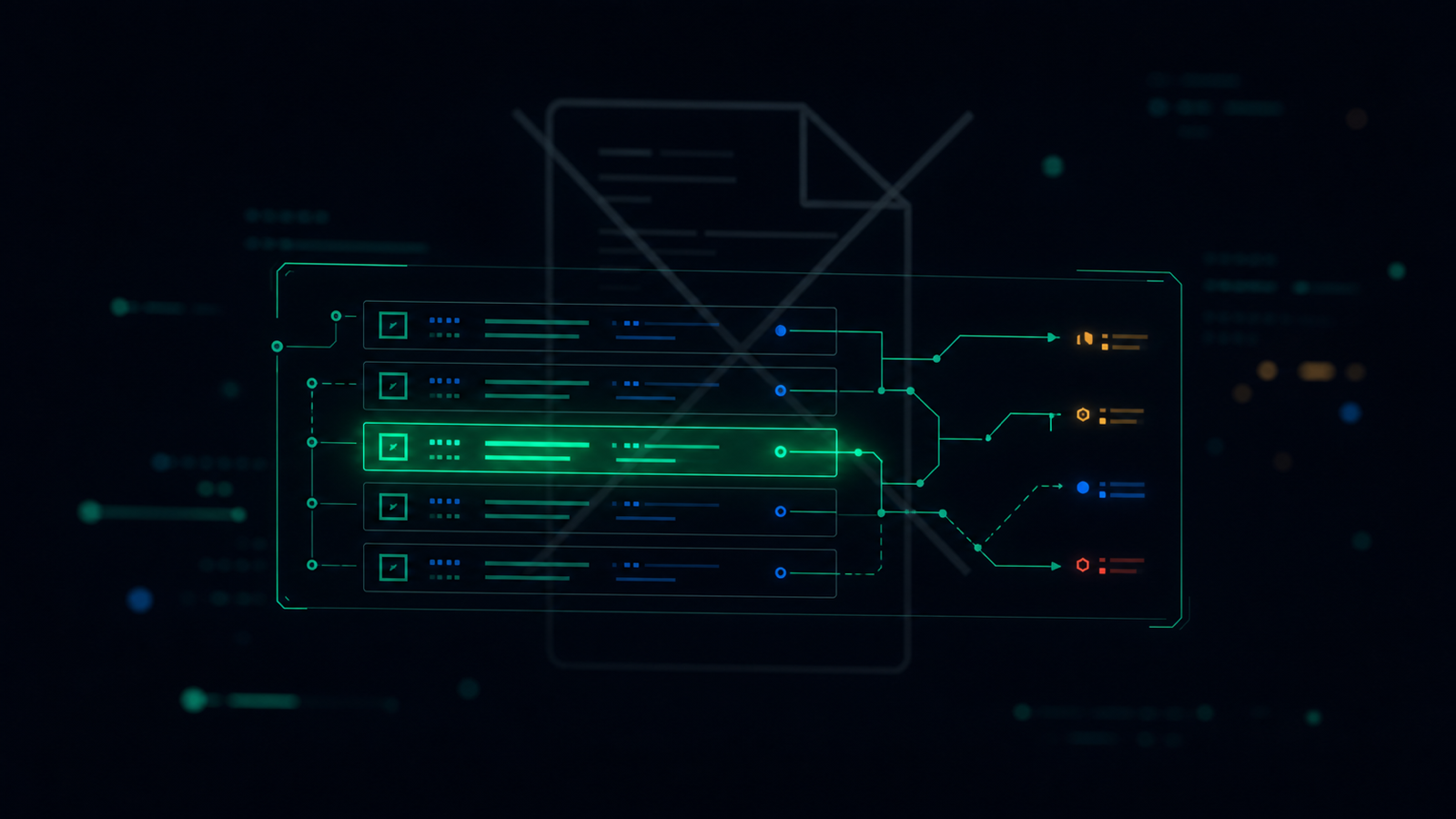
- AI 사용 정책 — 어떤 AI 도구를 어떤 용도로 허용/금지하는지, 어떤 데이터 유형(개인정보·기밀 등)을 넣으면 안 되는지, 위반 시 절차는 무엇인지 문서화한 것. 승인·개정 이력 포함.
- 차단·마스킹 로그 — 정책이 실제로 작동했다는 기록. "언제, 어떤 유형의 민감정보가, 어떤 서비스로 나가려다, 차단/마스킹됐다"를 남깁니다. 단, 원문이 아니라 유형과 조치만.
- 조치·예외 이력 — 위반·경고 발생 시 무엇을 했는지(교육, 재발 방지, 승인된 예외 처리 등). 통제가 살아 움직인다는 증거입니다.
- 주기적 리포트 — 기간별 통제 현황 요약(탐지/차단 건수, 위험도 분포, 추세). 심사관에게 "상시 운영되는 체계"임을 보여주는 상위 뷰입니다.
정책은 "우리가 무엇을 하기로 했는가", 로그·이력은 "실제로 작동했는가", 리포트는 "체계로 굴러가는가"를 증명한다. 세 층이 다 있어야 하나의 완결된 증적이 된다.
원문 없이 증적을 성립시키는 논리
여기가 이 글의 핵심입니다. "차단했다는 걸 어떻게 믿나 — 원문을 보여줘야 하지 않나?"라는 반문에 답하는 논리입니다. 답은 원문이 아니라 메타데이터와 해시로 검증 가능성을 만든다는 것입니다.
하나의 탐지·차단 이벤트를 이런 필드로 기록한다고 해봅시다.
event_id: evt_2026-07-02_0931_ab12
timestamp: 2026-07-02T09:31:44+09:00
data_type: RESIDENT_NO # 민감정보 "유형"만 (값 아님)
service: external-ai-chat # 어떤 외부 AI 서비스로 향했는지
action: BLOCKED # 차단 / 마스킹 / 경고 / 허용
severity: HIGH # 위험도
content_hash: 3f9a…c7 (SHA-256) # 원문의 지문 — 원문 자체는 저장 안 함이 레코드에는 사람이 입력한 문장 원문도, 주민번호 값 자체도 없습니다. 그런데도 심사가 요구하는 것을 전부 충족합니다.
- 유형(data_type) — 어떤 종류의 민감정보였는지. 값이 아니라 분류.
- 서비스·시간(service·timestamp) — 어디로, 언제 나가려 했는지.
- 조치(action)·위험도(severity) — 통제가 실제로 무엇을 했는지.
- 해시(content_hash) — 원문의 단방향 지문. 원문을 보관하지 않아도, 특정 원문이 이 이벤트와 일치하는지 사후 대조·무결성 검증이 가능합니다. 해시로 원문을 복원할 수는 없습니다.
해시는 "원문을 저장하지 않았다는 것"과 "그럼에도 특정 사건을 검증할 수 있다는 것"을 동시에 성립시킨다. 이게 원문 미저장 설계가 오히려 더 신뢰받는 이유다.
즉, 심사 논리는 이렇게 완성됩니다 — 정책(했어야 할 것) + 메타데이터 로그(실제 작동) + 해시(무결성) + 조치 이력(후속) = 완결된 통제 증적. 원문은 이 사슬 어디에도 필요하지 않습니다.
"로그 남기려다 원문 수집" 딜레마 피하기
많은 조직이 빠지는 함정이 있습니다. "증적을 확실히 하려고" 프롬프트·파일 원문을 통째로 저장하는 방식입니다. 이건 세 가지 이유로 나쁜 선택입니다.
- 새로운 위험 저장소를 만든다 — 직원들이 입력한 개인정보·기밀이 한곳에 쌓입니다. 그 저장소 자체가 최우선 유출 표적이 되고, 개인정보 최소수집 원칙과도 충돌합니다.
- 직원 신뢰를 무너뜨린다 — "내 입력이 다 저장된다"는 인식은 곧 우회로 이어집니다. 통제가 감시로 인식되면 체계가 죽습니다.
- 증적 품질을 높이지도 않는다 — 심사관이 원하는 건 원문 더미가 아니라 검증 가능한 통제의 흔적입니다. 원문은 증적 가치는 낮고 위험만 큽니다.
그래서 설계 원칙은 명확합니다 — 탐지는 로컬에서, 서버로는 유형·조치·해시 같은 메타데이터만. 원문은 사용자 기기를 떠나지 않습니다. 이렇게 하면 증적은 성립하고, 위험 저장소는 애초에 생기지 않습니다.
탐지는 사용자 단에서 수행하고, 서버로는 rule_id·유형·조치·위험도·해시 같은 메타데이터만 전송합니다. 프롬프트·파일 원문은 저장하지 않습니다. 그 결과가 곧 심사에 올릴 수 있는 로그·리포트가 됩니다. 설계 원칙은 보안 페이지에서, 규제 매핑은 ISMS-P·감사 솔루션에서 확인하세요. 자체 인증(SOC 2·ISMS-P)은 취득 예정이며, 상세 문서는 백서로 제공합니다.
심사 대비 준비 절차
증적 4종을 실제로 갖추는 순서입니다.
- 정책 문서화·승인 — 허용/금지 AI 도구, 금지 데이터 유형, 위반 절차를 문서로 만들고 결재·개정 이력을 남깁니다.
- 기술 통제 배치 — 실제 입력 단계에서 민감정보를 탐지·차단·마스킹하는 통제를 둡니다. 이 통제가 로그를 생성합니다.
- 메타데이터 로그 스키마 확정 — 유형·서비스·시간·조치·위험도·해시 필드를 정의하고, 원문성 필드는 스키마에서 배제합니다.
- 조치 프로세스 연결 — 경고·위반이 뜨면 누가 무엇을 하는지 절차를 정하고 이력을 남깁니다.
- 정기 리포트 자동화 — 월/분기 단위로 탐지·차단 통계와 추세를 요약해 상위 뷰로 만듭니다.
- 사전 자체 점검 — 심사 전에 "정책·로그·조치·리포트"를 실제 사건 하나로 처음부터 끝까지 연결해 봅니다. 사슬이 끊기는 지점이 곧 심사 지적 지점입니다.

증적 준비 체크리스트
- 외부 생성형 AI 사용 정책이 문서화되고 승인·개정 이력이 있는가?
- 금지 데이터 유형(개인정보·기밀 등)이 정책에 명시돼 있는가?
- 입력 단계에서 민감정보를 탐지·차단/마스킹하는 기술 통제가 있는가?
- 로그가 원문이 아니라 유형·서비스·시간·조치·위험도로 남는가?
- 각 이벤트에 무결성 검증용 해시가 포함되는가?
- 프롬프트·파일 원문을 서버에 저장하지 않는 설계인가?
- 위반·경고에 대한 조치 이력이 기록되는가?
- 주기적 통제 현황 리포트가 자동으로 생성되는가?
- "정책→로그→조치→리포트"를 실제 사건 하나로 연결해 봤는가?
세 개 이상 "아니오"라면, 심사 전에 지금 메우기 시작해야 합니다.